IT/모바일 >
TensorFlow로 SNS의 대화를 이용해 주식 시장을 예측하는 멀티레이어 LSTM 네트워크 구현하기
Long short-term memory (LSTM) 네트워크가 소개된 지 20여년이 되었는데, (Hochreiter and Schmidhuber, 1997), 최근 몇 년 사이에 엄청난 인기와 성과를 보이고 있다. LSTM 네트워크는 recurrent neural network (RNN) - 순차 데이터를 모델링하는데 사용되는 neural network으로, 주로 자연어 처리(NLP)에 사용된다. - 의 특수한 버전이다. LSTM은 오래된 정보를 계속 유지할 수 있어서, 시퀀스의 초기에 입력된 중요한 정보가 시퀀스의 마지막에 큰 영향을 줄 수 있는 것이 전통적인 RNN과 비교했을 때 이점이다.
이 튜토리얼에서는, LSTM 네트워크의 구조를 설명하고, StockTwits의 메시지로부터 주식 시장을 예측하는 LSTM을 만들어 보고자 한다. 우리는 간단하고, 높은 수준의 명령어들을 제공하며, 최근 아주 유명해진 TensorFlow를 이용할 것이다.
LSTM 셀과 네트워크 구조
우리의 네트워크를 만들기 전에, LSTM 셀이 동작하는 방식과 구조에 대해서 살펴 보도록 하자. (그림1)
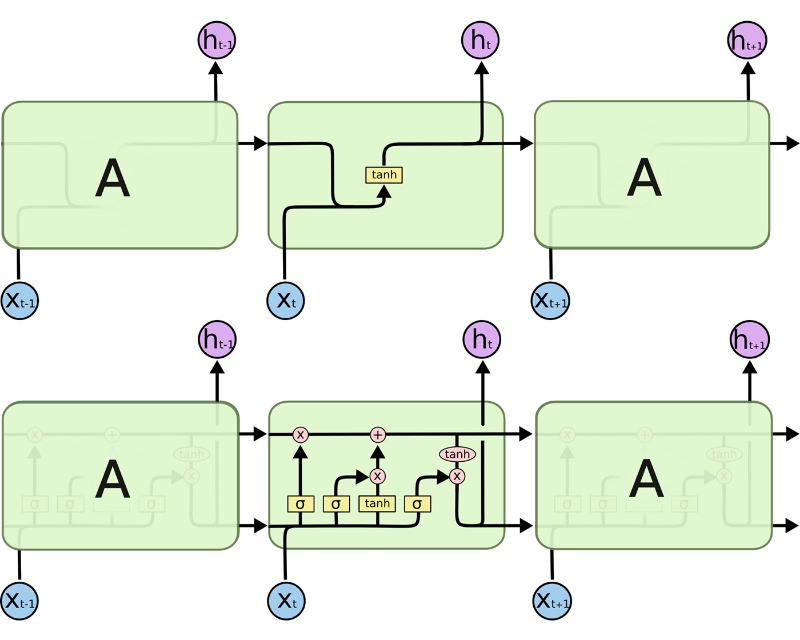
[그림1] 그림으로 펼쳐진 RNN 셀 구조(위)와 LSTM 셀 구조 (아래)
RNN 셀을 나타내기 위해서는, 현재 입력 시퀀스 (우리의 경우 현재 입력되는 단어) xi, 현재의 hidden state의 output인 hi가 필요하며, 이는 다음 RNN 셀의 입력으로 사용된다. LTSM의 내부는 전통적인 RNN보다 좀 더 복잡하다. 전통적인 RNN셀이 현재 상태(ht−1)와 입력(xt)에 대해 하나의 내부 레이어를 가지고 있는 반면, LSTM은 3개를 가지고 있다.
우선 이전 상태로부터 어떤 데이터가 남겨질지 조절하는 "forget gate"가 있다. 이 레이어는 이전 셀의 output인 ht−1과 현재의 입력인 xt를 시그모이드 활성 레이어(σ)에 적용해 각 hidden unit별로 0과 1사이의 값을 얻는다. 이 값을 현재 상태와 element끼리 곱한다. (그림1의 "위쪽 컨베이어 벨트"의 첫번째 동작이다.)
다음으로 현재 입력에 따라 state를 업데이트하는 "update gate"가 있다. 이 레이어는 동일한 입력 (ht−1 과 xt)을 시그모이드 활성 레이어(σ)와 tanh 활성 레이어 (tanh)에 넣은 후, 각 결과를 element끼리 곱한다. 그 다음, 이 결과와 "forget gate"를 통과한 현재 상태를 element끼리 더해 새로운 정보를 이용해 상태 값을 업데이트한다. (그림1의 "위쪽 컨베이어 벨트"의 두번째 동작이다.)
마지막으로, 다음 단계로 넘길 정보를 조절하기 위한 "output gate"가 있다. 현재 상태를 tanh 활성 레이어(tanh)에 통과시킨 결과를, 셀 input(ht−1 과 xt)을 시그모이드 활성 레이어(σ)에 통과시킨 결과와 element끼리 곱한다. 이 과정이 우리가 어떤 결과를 내보내줄 것인지 필터링하는 역할을 수행한다. 이 결과인 ht가 다음 시퀀스의 입력으로 넘겨지며, 또한 우리 네트워크의 다음 레이어로 전달된다.
이제 LSTM을 좀 더 잘 이해하게 되었으니, 그림2에서 LSTM 네크워크 구조의 예시를 살펴보도록 하자.
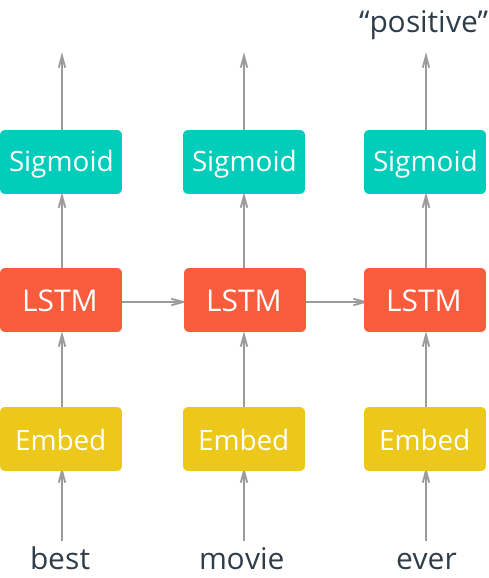
[그림2] 임베딩 레이어까지 함께 표현된, 펼쳐진 싱글 레이어 LSTM 네트워크
그림2에서, 임베딩 레이어와 그 뒤를 이어 LSTM 그리고 시그모이드 활성 함수가 연결되어 있는 '펼쳐진' LSTM 네트워크를 볼 수 있다. 우리는 입력값이, 이 경우 영화 리뷰에 사용된 단어들이, 순차적으로 입력되는 것을 확인할 수 있다.
우선 단어들은 임베딩 값을 찾는다. 텍스트 데이터를 사용하는 경우 대부분, 사전 크기가 매우 크다. 이 때문에 워드 임베딩을 사용하는 것이 (정확도와 효율 측면에서) 종종 더 이득이다. 이것은 단어를 벡터 스페이스에 다차원적이고 분산적으로 표현한 방식이다. 이러한 임베딩을 학습하기 위해서는 word2vec과 같은 다른 딥러닝 기법을 사용할 수도 있고, 우리가 할 방법과 같이, end-to-end 방식으로 모델을 학습시킬 수도 있다.
이러한 임베딩은 LSTM 레이어의 입력으로 사용되고, 그 결과는 시그모이드 결과 레이어와 입력 시퀀스의 다음 단어에서 사용할 LSTM 셀로 전달된다. 우리의 경우, 우리는 모든 시퀀스가 입력되고 난 후의 결과만 사용할 것이기 때문에, 시퀀스의 마지막 단어가 사용된 시그모이드 활성 레이어의 결과만 고려할 것이다
설정
이 튜토리얼에서 사용할 코드는 GitHub에서 받을 수 있다. 모든 필요사항들은 README 파일에 기술되어 있다.
StockTwits $SPY 메시지 데이터 셋
우리는 주식 시장에 대한 글들을 분석해서 개인들의 주식 시장 예측을 판단하는 LSTM을 만들고자 한다.
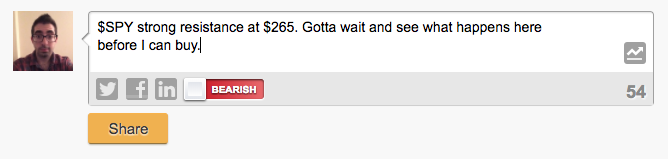
[그림3] 하락세를 예상하는 StockTwits 메시지 예시.
우리는 StockTwits.com으로부터 S&P 500 인덱스 펀드를 뜻하는 $SPY 태그가 달린 메시지들을 이용해 모델을 학습할 것이다. StockTwits는 주식 매매자들과 투자자들이 주식 시장에 대한 관점을 공유하기 위한 소셜 미디어이다. 사용자들이 메시지를 작성할 때에는 관련된 주식을 태그로 표시하고, 예측을 표시할 수 있다. 예를 들어, "bullish"는 주식이 상승할 것을, "bearish"는 하락할 것을 예상하는 것이다. 그림3에서 샘플 메시지를 확인할 수 있다.
우리의 데이터 셋은 2017년에 $SPY로 태깅되고, 사용자들이 자신의 예측을 표현한 약 100,000개의 메시지로 구성되어 있다.
모델링을 위한 데이터 준비
모델링을 시작하기 전에, 데이터를 약간 손봐야 한다. GitHub repository에 우리 데이터를 전처리하기 위한 코드들이 있다. 이 함수들은 이 튜토리얼에서 수행할 많은 데이터 관련 작업들을 추상화했다. 하지만 분석을 위해 데이터를 어떻게 전처리하는지 좀 더 잘 이해하기 위해서 "util.py" 파일을 읽어보기를 권한다.
우선, 메시지에서 주식 관련 표현, 사용자, 링크 등 StockTwits의 알려진 객체로 정규화하는 전처리를 수행해야 한다. 또한, 구두점들은 모두 제거한다.
다음으로, 우리의 메시지와 예상 데이터를 인코딩 한다. 예상 정보는 하락은 0, 상승은 1로 간단히 정리할 수 있다. 메시지 데이터를 인코딩하기 위해서는, 메시지에서 모든 단어들을 추출한 후, 1부터 시작하는 인덱스에 각 단어들을 매핑한다. 실제로는 학습용 데이터에 있는 단어들만 사용하겠지만, 여기에서는 단순성과 데모 목적으로 전체 데이터에서 단어들을 추출한다. 이 매핑을 작업을 완료한 후, 메시지들의 단어를 적절한 index로 치환한다.
모든 입력 데이터들이 동일한 크기를 갖도록 하기 위해, 최대 길이의 시퀀스를 찾고, 최대 길이에 맞추기 위해 다른 메시지들에는 0을 추가한다. 우리의 경우 모든 메시지들을 "왼쪽에 0을 채워서" 최대 길이(244개 단어)로 맞추었다.
마지막으로, 데이터를 학습용, validation용, 평가용으로 나누었다.
네트워크 입력
Neural network를 만들면서 가장 먼저 할 일은 입력값을 정의하는 것이다. 여기에서는 메시지 시퀀스, 레이블, 그리고 dropout을 나타내는 "유지 확률" 변수를 정의하는 TensorFlow placeholder를 만드는 함수를 정의한다.
def model_inputs():
"""
Create the model inputs
"""
inputs_ = tf.placeholder(tf.int32, [None, None], name='inputs')
labels_ = tf.placeholder(tf.int32, [None, None], name='labels')
keep_prob_ = tf.placeholder(tf.float32, name='keep_prob')
TensorFlow placeholder는 우리가 학습을 위해 네트워크에 입력하는 데이터가 통과하는 "파이프"라고 할 수 있다.
임베딩 레이어
다음으로, 임베딩 레이어를 만들 함수를 정의한다. TensorFlow에서는, 워드 임베딩을 행은 단어를, 그리고 열은 임베딩을 의미하는 매트릭스로 표현한다. (그림4 참고) 각각의 weight는 학습 과정에서 학습하게 된다.
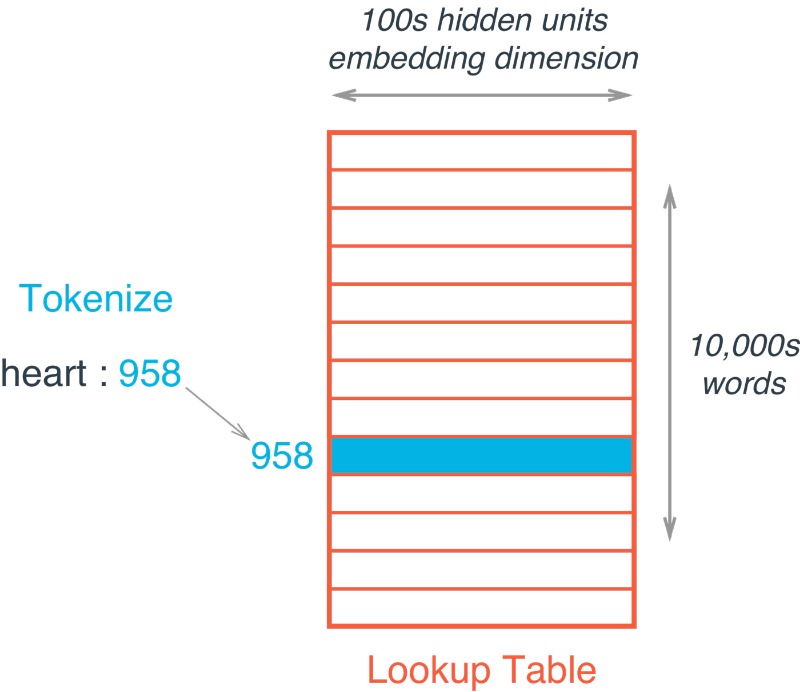
[그림4] 단어 10,000개와 임베딩 사이즈가 100인 임베딩 예
임베딩 참조는 현재 단어의 인덱스를 이용해 단순히 임베딩 매트릭스를 참조하면 된다
def build_embedding_layer(inputs_, vocab_size, embed_size):
"""
Create the embedding layer
"""
embedding = tf.Variable(tf.random_uniform((vocab_size, embed_size), -1, 1))
embed = tf.nn.embedding_lookup(embedding, inputs_)
이제 얻게 되는 단어의 임베딩 벡터는 분산 표현을 갖게 된다 - 즉, 현재 단어의 다차원 벡터로서, LSTM 레이어로 전달된다.
LSTM 레이어
우리는 동적으로 레이어 수와 크기를 조절할 수 있는 LSTM 레이어를 만드는 함수를 정의할 것이다. 이 함수는 LSTM 크기의 리스트를 받는데, 이 리스트의 길이가 곧 LSTM 레이어의 개수가 된다. (예를 들어, 우리는 예시에서 크기 값으로 128과 64를 갖는 길이가 2인 리스트를 사용할 것이다. 이것은 곧 첫번째 LSTM 레이어의 히든 레이어 크기가 128이고 두번째 레이어의 히든 레이어는 64인 2개 레이어로 구성된 LSTM 네트워크를 뜻한다.)
우선, TensorFlow contrib API의 BasicLSTMCell을 이용해 LSTM 레이어를 만들고, 각각의 레이어를 dropout 레이어로 감싼다.
여기에서는 단순히 보여주기 위한 목적으로 BasicLSTMCell을 사용한다는 것을 명심하길 바란다. 실제로는 네트워크 구성시 사용할 수 있는 더 성능이 좋은 방법들이 많다. 예를 들어 tf.contrib.cudnn_rnn.CudnnCompatibleLSTMCell의 경우 BasicLSTMCell보다 20배는 더 빠르면서 3~4배 정도 메모리를 절약할 수 있다.
Dropout은 딥러닝에서 주로 정규화를 위해 사용하는 기법인데, 각각의 노드들이 학습이 진행되는 동안 "떨어져 나갈(dropping out)" 확률을 가지고 있는 것이다. 실제 문제를 해결할 때 이러한 정규화 기법을 사용하는 것이 좋다. 이러한 기법들이 모델이 특정 노드에 지나치게 의존적이지 않게 만듦으로써 새로운 데이터도 잘 처리할 수 있도록 모델을 일반화 시킨다.
def build_lstm_layers(lstm_sizes, embed, keep_prob_, batch_size):
"""
Create the LSTM layers
"""
lstms = [tf.contrib.rnn.BasicLSTMCell(size) for size in lstm_sizes]
# Add dropout to the cell
drops = [tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=keep_prob_) for lstm in lstms]
# Stack up multiple LSTM layers, for deep learning
cell = tf.contrib.rnn.MultiRNNCell(drops)
# Getting an initial state of all zeros
initial_state = cell.zero_state(batch_size, tf.float32)
lstm_outputs, final_state = tf.nn.dynamic_rnn(cell, embed, initial_state=initial_state)
이렇게 dropout으로 감싸진 LSTM들이 TensorFlow의 MultiRNN 셀로 전달되어 layer들이 쌓이게 된다. 마지막으로, 시작 상태를 생성한 후, 쌓여져 있는 LSTM 레이어, 이전에 정의한 임베딩으로 부터 얻은 input, 그리고 시작 상태를 전달해 네트워크를 생성한다. TensorFlow dynamic_rnn을 사용하면 모델의 결과와 마지막 상태값을 반환하는데, 이것들이 학습하는 동안 배치 사이에서 전달되어야 한다.
Loss function, 최적화 방법, 그리고 정확도
마지막으로, 우리 모델의 loss function, 최적화 방법, 그리고 정확도를 정의하기 위한 함수를 생성한다. loss와 정확도가 단순히 결과 값에서 계산하는 것에 불과하더라도, TensorFlow에서는 모든 과정이 계산 그래프의 일부이다. 그렇기 때문에, 우리는 loss, 최적화 방법, 그리고 정확도 계산 노드를 그래프의 관점에서 정의할 필요가 있다.
def build_cost_fn_and_opt(lstm_outputs, labels_, learning_rate):
"""
Create the Loss function and Optimizer
"""
predictions = tf.contrib.layers.fully_connected(lstm_outputs[:, -1], 1, activation_fn=tf.sigmoid)
loss = tf.losses.mean_squared_error(labels_, predictions)
optimzer = tf.train.AdadeltaOptimizer (learning_rate).minimize(loss)
def build_accuracy(predictions, labels_):
"""
Create accuracy
"""
correct_pred = tf.equal(tf.cast(tf.round(predictions), tf.int32), labels_)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
우선, LSTM의 결과를 TensorFlow fully connected layer를 통해 시그모이드 활성 함수에 전달해 예측값을 얻는다. LSTM 레이어는 입력 시퀀스의 모든 단어들에 대한 결과를 내준다는 것을 기억해야 한다. 하지만, 우리는 예측값을 얻기 위해 가장 마지막 결과만 필요하다. 이를 위해 위에서 보여준 바와 같이, [:, -1] 인덱싱을 이용해 해당 값을 얻어 시그모이드 활성 함수를 사용하는 하나의 fully connected layer에 전달해 예측값을 얻는다. 이 예측값은 mean squared error loss function으로 전달되며, Adadelta optimizer를 이용해 이 loss를 최소화 하도록 모델을 학습한다. 마지막으로, 학습, validation, 평가 셋에서 모델 성능을 정의하기 위한 정확도를 정의한다.
그래프 생성하고 학습하기
이제까지 우리는 계산 프래프의 각 조각을 생성하기 위한 함수를 정의했다. 이제 계산 그래프를 만들고, 학습을 하는 함수를 하나 더 정의해야 한다. 우선 네트워크를 만들기 위해 우리가 정의한 함수들을 호출하고, 그 후에 mini-batch를 이용해 미리 정의된 epoch 수 만큼 모델을 학습하기 위해 TensorFlow session을 호출한다. 매 epoch마다 학습 결과를 모니터하기 위해 loss, training 정확도, 그리고 validation 정확도를 출력한다.
def build_and_train_network(lstm_sizes, vocab_size, embed_size, epochs, batch_size,
learning_rate, keep_prob, train_x, val_x, train_y, val_y):
# Build Graph
with tf.Session() as sess:
# Train Network
# Save Network
다음으로, 우리 모델의 hyper parameter를 정의해야 한다. 우리는 각 hidden layer의 크기가 128과 64인 두개 레이어를 갖는 LSTM 네트워크를 사용했다. 그리고 크기가 300인 임베딩을 사용했으며, 크기가 256인 mini-batch를 이용해 50 epoch 동안 모델을 학습했다. 초기 학습률로 0.1을 사용했지만 학습 과정에서 Adadelta optimizer가 이 값을 적절히 수정했을 것이다. 그리고 keep probability로 0.5를 사용했다.
결과를 보면, 우리의 LSTM 네트워크는 학습이 빨리 되는 것을 알 수 있다. 첫 epoch에서 58%인 validation 정확도가 10번째 epoch 이후에 66%로 상승했다. 이후로는 학습 속도가 줄기 시작해, 50 epoch가 지난 후에는 training 정확도는 75%, validation 정확도는 72%가 되었다. 모델 학습이 완료된 후에는 TensorFlow saver를 이용해 모델 파라미터들을 추후에 사용할 수 있도록 저장했다.
Epoch: 1/50... Batch: 303/303... Train Loss: 0.247... Train Accuracy: 0.562... Val Accuracy: 0.578
Epoch: 2/50... Batch: 303/303... Train Loss: 0.245... Train Accuracy: 0.583... Val Accuracy: 0.596
Epoch: 3/50... Batch: 303/303... Train Loss: 0.247... Train Accuracy: 0.597... Val Accuracy: 0.617
Epoch: 4/50... Batch: 303/303... Train Loss: 0.240... Train Accuracy: 0.610... Val Accuracy: 0.627
Epoch: 5/50... Batch: 303/303... Train Loss: 0.238... Train Accuracy: 0.620... Val Accuracy: 0.632
Epoch: 6/50... Batch: 303/303... Train Loss: 0.234... Train Accuracy: 0.632... Val Accuracy: 0.642
Epoch: 7/50... Batch: 303/303... Train Loss: 0.230... Train Accuracy: 0.636... Val Accuracy: 0.648
Epoch: 8/50... Batch: 303/303... Train Loss: 0.227... Train Accuracy: 0.641... Val Accuracy: 0.653
Epoch: 9/50... Batch: 303/303... Train Loss: 0.223... Train Accuracy: 0.646... Val Accuracy: 0.656
Epoch: 10/50... Batch: 303/303... Train Loss: 0.221... Train Accuracy: 0.652... Val Accuracy: 0.659
테스트
마지막으로, 우리의 모델이 학습되는 동안 validation 셋에서 보여준 것과 같이, 우리가 기대하는 모습을 보여줄지 확인하기 위해 test 셋에 모델을 적용시켜 보았다.
def test_network(model_dir, batch_size, test_x, test_y):
# Build Network
with tf.Session() as sess:
# Restore Model
# Test Model
이전에 했던 것처럼 계산 그래프를 만들었지만, 이전에는 학습을 한 반면, 이번에는 체크아웃 디렉토리에 저장한 모델을 로드해서 평가용 데이터를 모델에 적용했다. 평가 정확도는 72%이다. 이것은 우리의 validation 정확도와 같은 양상을 보이는 것이고, 곧 우리가 데이터 분포를 잘 잡아냈다는 것을 뜻한다.
INFO:tensorflow:Restoring parameters from checkpoints/sentiment.ckpt
Test Accuracy: 0.717
결론
우리는 훌륭하게 첫 발을 내딛었지만, 여기에서도 모델 성능을 향상시키기 위한 몇가지 작업들을 수행할 수 있다. 모델을 더 오래 학습 시킬수도 있고, 더 많은 hidden unit과 LSTM 레이어로 더 큰 네트워크를 구축할 수도 있으며, hyperparameter들을 튜닝할 수도 있다.
요약하자면, LSTM 네트워크는 RNN의 확장으로, 입력 데이터의 긴 기간 동안 의존성 있는 학습 문제를 처리하기 위해 설계되었다. LSTM은 순차 데이터를 처리하기에 적합하며, NLP 문제를 해결하는데 종종 사용된다. 우리는 소셜 미디어의 글로부터 주식 시장을 예측하는 모델을 워드 임베딩을 사용한 멀티 레이어 LSTM 네트워크로 학습함으로써, LSTM의 능력을 보여주었다.
*****
원문 : Introduction to LSTMs with TensorFlow
번역 : 한승균
이전 글 : 리액트를 배우기 전에 알아야할 5가지
다음 글 : 강력한 디자인 경험을 만들고 성장하는 방법



최신 콘텐츠