IT/모바일
제공 : 한빛 네트워크
저자 : Liliana Bounegru
역자 : 구혜정
원문 : A brief history of data journalism
 다음은 데이터 저널리즘의 성장에 대해 다루는 에세이와 자료의 모음인 "데이터 저널리즘 핸드북"에서 발췌한 것입니다.
다음은 데이터 저널리즘의 성장에 대해 다루는 에세이와 자료의 모음인 "데이터 저널리즘 핸드북"에서 발췌한 것입니다.
2010년 8월 몇몇 동료와 나는 암스테르담에서 우리가 최초라고 믿는 최초의 국제적인 "데이터 저널리즘" 컨퍼런스를 개최했다. 이때만 해도, 이 주제에 대해 많은 토론이 이루어지지 않고 있었으며, 이 분야에서 이룬 위대한 업적을 바탕으로 유명세를 탄 몇몇 조직만이 있을 뿐이었다.
 가디언이나 뉴욕타임즈와 같은 미디어 조직은 "데이터 저널리즘"이라는 용어를 유명하게 만든 주인공 중의 하나인 위키리크스에 의해 발표된 많은 양의 데이터를 다뤘다. 이 시기에 "데이터 저널리즘"은 "컴퓨터-활용 보도"와 함께 기자들이 자신들이 다뤄야 할 주제에 대해 더 철저하게 조사하며, 그들의 보도의 질을 향상시키기 위해 어떻게 데이터를 이용하는지 설명하기 위해 더 널리 사용되기 시작한 단계였다.
가디언이나 뉴욕타임즈와 같은 미디어 조직은 "데이터 저널리즘"이라는 용어를 유명하게 만든 주인공 중의 하나인 위키리크스에 의해 발표된 많은 양의 데이터를 다뤘다. 이 시기에 "데이터 저널리즘"은 "컴퓨터-활용 보도"와 함께 기자들이 자신들이 다뤄야 할 주제에 대해 더 철저하게 조사하며, 그들의 보도의 질을 향상시키기 위해 어떻게 데이터를 이용하는지 설명하기 위해 더 널리 사용되기 시작한 단계였다.
풍부한 경험이 있는 데이터 저널리스트와 데이터 저널리즘 학자와 트위터로 얘기하는 것이 우리가 현재 데이터 저널리즘이라고 부르는 것이고, 이것은 EveryBlock의 설립자인 Adrian Holovaty에 의해 명명되었으며, 초기에는 데이터 저널리즘을 포함한 다른 많은 명칭들도 존재했었다. 그의 짧은 에세이인 "변경되어야 하는 신문사의 근본 방식"에서 그는 저널리스트들이 전통적인 "big bob of text"처럼 구조화되고 기계가 인식할 수 있는 데이터를 발표해야 한다고 주장했다. :
"컴퓨터-활용 보도" 그리고 "정밀 저널리즘"
보도를 향상시키기 위해 데이터를 사용하는 것과 대중에게 (만약 기계가 인식할 수 없도록)구조화된 정보를 전달하는 것은 긴 역사를 가진다. 아마도 우리가 현재 데이터 저널리즘이라고 부르는 것과 가장 직접적으로 관련 있는 것은 최초로 체계가 잡힌 "컴퓨터-활용 보도" 혹은 "CAR" 이며, 더욱 향상된 뉴스를 제공하기 위해 데이터 수집과 분석을 위해 컴퓨터를 사용한 체계적 시도이다.
CAR은 1952 년에CBS에서 대통령 선거의 결과를 예측하기 위해 최초로 사용되었다. 1960년대 이후로 (주로 미국을 기반으로 조사하는 저널리스트들이 과학적으로 공공 기록 데이터베이스 분석하여 독립적으로 모니터링하는 방법을 추구했었다. 또한 "public service journalism"으로 알려진 이들의 컴퓨터-활용 기술의 지지자들은 트렌드를 파악하고, 일반적인 지식이 틀렸음을 증명하고, 공공 단체들과 법인들에 의해 저질러진 불법적인 것들을 드러내는 것을 추구했었다. 예를 들어, Philip Meyer은 디트로이트에서 일어난 1967 폭동에 대해 받은 기사가 틀렸음을 증명하였고, 이 폭동에 참가했던 사람들은 덜 교육받은 남부인들 뿐만이 아니라는 것을 보여주었다. 1980년대에 발행된 Bill Deadman의 "The Color of Money" 책은 주요 금융 연구소들의 제도적 인종 차별을 폭로했다. 그의 책인 "What Went Wrong?"에 있는 Steve Doig는 결함이 있는 도시 개발 정책과 관행들의 영향력을 이해하기 위해서 1990년대 초의 "허리케인 앤드루"의 피해 패턴 분석하는 것을 추구했다. 데이터-주도 보고는 가치 있는 공공 서비스를 초래했고, 그는 영예 기자상을 수상했다.
1970대 초반 취재의 새로운 형태인 이것을 설명하기 위해 "precision journalism"이라는 새로운 단어가 만들어졌다. : "저널리즘의 실천방법에 대한 사회과학과 행동과학의 갖가지 조사 방법의 적용". 정밀 저널리즘은 저널리즘과 사회과학 분야에서 전문적으로 훈련된 전문가들에 의해 주요 미디어 연구소들에서 실습되면서 가시화 되었다. 이것은 소설 기법이 보도에 적용되는 저널리즘의 형태인 "새로운 저널리즘"에 대한 반응으로부터 생겨났다. Meyer는 오히려 문학적인 기법 보다는 데이터 수집 및 분석을 하는 과학 기술이 객관성과 진실성에 대한 조사를 수행하는 저널리즘을 위해 필요하다고 제안하였다.
정밀 저널리즘은 저널리즘의 일반적인 인용의 부적절성과 약점 중 일부에 대한 반응으로 이해할 수 있다. : 대 언론 공식 발표(후세에서는 "churnalism(처널리즘)"으로 불리 우는)에 대한 의존과 권위 있는 출처에 대한 편견, 그리고 기타 등등. 이러한 것들은 Meyer에 의해 정보 과학 기술과 여론 조사와 공공 기록 같은 과학적 방법의 응용 부족으로부터 발생한 것으로 보여졌다. 1960년대 실행된 대로, 정밀 저널리즘은 비주류 집단과 그들의 이야기를 표현하는데 사용되었다. Meyer의 말에 따르면, :
우리가 예상한 대로, 보도를 향상시키기 위해 데이터를 사용하는 실천방법들은 주위에 "데이터"가 존재하기 시작한 때까지 거슬러 올라간다. Simon Rogers가 지적한 바와 같이, 데이터 저널리즘의 첫 사례는 1821년부터 가디언사에서 발생하였다. 그것은 맨체스터에 있는 학교들의 학교당 비용과 학생의 수를 목록화 한 유출된 표였다. Rogers에 따르면 이것은 공식적으로 발표된 숫자보다 훨씬 많은, 자유 교육을 받는 실제 학생들의 수를 처음으로 보여주는 것을 도왔다고 한다.
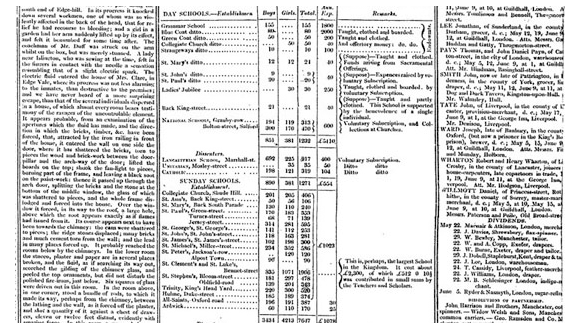
[그림] 1821년 가디언에 게재된 데이터 저널리즘
유럽의 다른 초기 예는 1958년에 출판된 Florence Nightingale과 그녀의 주요 보고서인 "Mortality of the British Army"이다. 의회에 제출한 그녀의 보고서에는 그녀는 영국 육군에 대한 의료 서비스 개선을 옹호하기 위해 그래픽을 사용했다고 한다. 가장 유명한 것은 그녀의 "coxcomb"(장미도표)이다. 이것은 섹션들이 나선형을 이루고 있는 것으로, 각 달의 사망자 수를 나타내고 있는데, 죽은 이들의 절대 다수는 총상 보다는 예방할 수 있었던 질병에 걸려 죽었다고 강조했다.
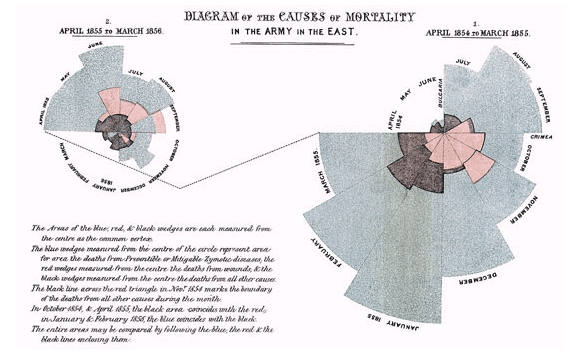
[그림] Florence Nightingale이 만든 영국 육군의 사망자 수 도표
데이터 저널리즘 그리고 컴퓨터-활용 보도
현재 "continuity and change(지속성과 변화)"와 이전 저널리즘 방법(데이터 세트를 분석하기 위한 전산 기법을 사용하는 방법)들과 이것들의 관계에 대한 토론이 "데이터 저널리즘" 주위에서 일어나고 있다.
CAR과 데이터저널리즘의 차이에 대해서 몇몇 의견 차이가 있다. 그들은 CAR은 (통상 조사하는)보도의 질을 높이기 위한 방법으로 단지 데이터를 분석하고 수집하기 위한 기술일 뿐이라고 말한다. 반면에 데이터 저널리즘은 저널리스트의 전체 작업 흐름에 연관되어 있는 데이터 시트자체에 주목한다. 이런 의미에서 데이터 저널리즘은 단순히 이야기를 찾거나 향상시키는 방법만큼(때때로는 더 많이, 데이터 그 자체에 주목하고, 단순히 데이터를 사용하는 것보다 더) 비용이 소요된다. 이런 이유로 우리는 가디언 데이터 블로그 또는 이야기와 함께 데이터 세트를 발표하는 Texas Tribune 또는 심지어 분석하고 탐구하는 사람들의 단순한 데이터 세트를 찾는다.
또 다른 차이점은 과거 조사 기자들은 그들이 대응하거나 언급하려 했던 이슈에 대한 문제와 관련 있는 정보의 부족으로 고생하곤 했다. 이것은 물론 아직도 여전히 사례일 뿐이지만, 이것은 또한 저널리스트들이 필수적으로 알아야 하는 정보가 아닌 정보의 압도적인 풍부함도 있다. 그들은 데이터가 아닌 것에서 가치를 얻는 방법을 모른다. 최근의 예는, 명백한 옹호 이후로 오랫동안 모색되었던, 그러나 발표된 이후로 많은 저널리스트들을 당황시키고 쩔쩔매게 했던 영국에서 가장 큰 지출 정보 데이터베이스인 COINS(통합 온라인 정보 체계)이다. Pilip Meyer가 최근에 나에게 이것을 써서 보낸 것은 다음과 같다 : "정보가 거의 없을 때에는, 우리 노력의 대부분은 정보를 찾고 모으는데 전념된다. 지금은 정보는 충분하기 때문에, 처리하는 것이 더욱 중요하다."
한 편, 일부는 데이터 저널리즘과 컴퓨터-활용 보도의 차이는 아주 근소한 것일 뿐이라고 주장한다. 현재의 관행에 의하면 심지어 최근 미디어 수행방법의 대부분은 역사 뿐만이 아니라 새로운 어떤 것도 내재하고 있다. 오히려 데이터 저널리즘에 대한 더욱 유익한 자세는 오랜 전통의 한 부분으로 그것을 받아들이는 것일 것이라는 견해가 완전히 소설인지 아닌지 논쟁하는 것 보다 새로운 상황과 조건에 대응해야 한다. 비록 목표와 기술에서의 차이가 없더라도, 세기 초의 "데이터 저널리즘"이라는 라벨의 출현은 이전보다 훨씬 더 많은 사람들이 더 많은 데이터를 이용하여, 더 쉽게 작업할 수 있도록 하는 정교한 사용자-중심 도구, 자기-출판 그리고 클라우드소싱 도구들과 결합하여 자유롭게 온라인으로 제공되는 데이터의 엄청난 양이라는 점에 대해서 새로운 국면을 나타낸다.
데이터 저널리즘이란 방대한 데이터를 읽고 사용할 줄 아는 능력
디지털 기술과 웹은 정보가 게시되는 방법의 근본적인 변화이다. 데이터 저널리즘은 데이터 시트와 서비스들 주위로 갑자기 생겨난 도구들과 방법들에 대한 생태계의 한 부분이다. 소스 자료의 인용과 공유는 웹을 비롯한 우리기에 익숙한 오늘날의 정보탐색구조에 사용되는 하이퍼링크 구조와 유사한 방식으로 이루어 진다. 더 멀리 거슬러 올라가면, 웹에 대한 하이퍼링크 구조의 근본 웹에 대한 하이퍼링크 구조를 기반으로 하는 것의 원칙은 학술적 작업에 사용되는 인용의 원칙이다. 이야기 뒤의 소스 자료와 데이터에 대한 인용과 공유는 위키리스크 설립자 Julian Assange가 "과학적 저널리즘"이라고 부른, 데이터 저널리즘이 저널리즘을 향상 시킬 수 있는 기본적인 방법들 중 하나이다.
누구나 데이터 원천 속으로 자료를 찾아 들어 가는 것과 그들에게 관련된 정보를 찾을 수 있게 하는 것 뿐만 아니라 사실 여부를 확인 하는 것과 일반적으로 받아들여지는 추정에 도전하는 것 을 가능하게 한 것을 통해, 데이터 저널리즘은 이전에 특정 분야의 전문가들(탐사기자들, 사회 과학자들, 통계학자들, 분석가들 또는 다른 분야의 전문가들 인지 아닌지 간에)만 사용하던 자료와 도구와 기술과 방법론들의 대중 민주화를 사실상 대표한다. 현재 데이터 원천의 인용과 연결은 데이터 저널리즘에 특별한 반면, 우리는 데이터가 미디어의 뼈대로 말끔히 통합되는 세계를 향해 움직이고 있다. 데이터 저널리스트는 데이터를 이해하고 데이터를 수집하는 장벽을 낮추는 것과 아주 많은 독자들의 데이터 활용능력을 높이는 것에 대해 중요한 역할을 하고 있다.
현재 그들 자신을 데이터 저널리스트들이라고 칭하는 사람들의 초기 커뮤니티는 더욱 성숙한 CAR 커뮤니티와 매우 큰 차이가 있다. 바라건대, 앞으로 우리가 새로운 NGO들과 시민 미디어 단체(ProPublica 및 탐사의 전통적 뉴스 미디어와 손을 잡고 일하는 탐사 보도의 Bureau 같은)에서 볼 수 있는 것 과 거의 비슷한 방식으로 두 커뮤니티 간에 강력한 유대관계를 볼 수 있길 바란다. 데이터 저널리즘이 데이터를 발표하고 기사를 제공하는 것에 대한 더 많은 창조적인 방법을 가지고 있을지라도, CAR 커뮤니티에 대한 철저하게 분석적이고 비판적인 접근은 데이터 저널리즘이 확실히 배워야 하는 그 무엇이다.
저자 : Liliana Bounegru
역자 : 구혜정
원문 : A brief history of data journalism
다음은 데이터 저널리즘의 성장에 대해 다루는 에세이와 자료의 모음인 "데이터 저널리즘 핸드북"에서 발췌한 것입니다.
2010년 8월 몇몇 동료와 나는 암스테르담에서 우리가 최초라고 믿는 최초의 국제적인 "데이터 저널리즘" 컨퍼런스를 개최했다. 이때만 해도, 이 주제에 대해 많은 토론이 이루어지지 않고 있었으며, 이 분야에서 이룬 위대한 업적을 바탕으로 유명세를 탄 몇몇 조직만이 있을 뿐이었다.
가디언이나 뉴욕타임즈와 같은 미디어 조직은 "데이터 저널리즘"이라는 용어를 유명하게 만든 주인공 중의 하나인 위키리크스에 의해 발표된 많은 양의 데이터를 다뤘다. 이 시기에 "데이터 저널리즘"은 "컴퓨터-활용 보도"와 함께 기자들이 자신들이 다뤄야 할 주제에 대해 더 철저하게 조사하며, 그들의 보도의 질을 향상시키기 위해 어떻게 데이터를 이용하는지 설명하기 위해 더 널리 사용되기 시작한 단계였다.
풍부한 경험이 있는 데이터 저널리스트와 데이터 저널리즘 학자와 트위터로 얘기하는 것이 우리가 현재 데이터 저널리즘이라고 부르는 것이고, 이것은 EveryBlock의 설립자인 Adrian Holovaty에 의해 명명되었으며, 초기에는 데이터 저널리즘을 포함한 다른 많은 명칭들도 존재했었다. 그의 짧은 에세이인 "변경되어야 하는 신문사의 근본 방식"에서 그는 저널리스트들이 전통적인 "big bob of text"처럼 구조화되고 기계가 인식할 수 있는 데이터를 발표해야 한다고 주장했다. :
"예를 들어, 신문이라고 말하는 것은 지역 화재에 대한 이야기로 쓰여 졌어요. 휴대폰으로 읽을 수 있도록 제작된 이 이야기는 꽤 멋진 것이었죠. 만세! 과학기술! 그러나 내가 정말로 하고 싶은 것은 그 이야기의 생생한 사실들을 하나하나, 속성 별로, 그리고 이전 화재와의 세부 항목의 비교를 위한 기반 구조(날짜, 시간, 장소, 희생자들, 소방서 번호, 소방서와의 거리, 소방대원의 이름과 경력, 소방대원이 도착하기 까지 걸린 시간)까지 살펴보는 것이었어요. 그리고 언제 발생했든지 간에 그 다음 화재들까지요."그러나 무엇이 데이터베이스나 컴퓨터를 사용하는 다른 저널리즘의 형식들과 차별점을 만드는 것일까? 어떻게, 또 어느 정도까지 데이터 저널리즘이 과거의 다른 형식의 저널리즘과 다를까?
"컴퓨터-활용 보도" 그리고 "정밀 저널리즘"
보도를 향상시키기 위해 데이터를 사용하는 것과 대중에게 (만약 기계가 인식할 수 없도록)구조화된 정보를 전달하는 것은 긴 역사를 가진다. 아마도 우리가 현재 데이터 저널리즘이라고 부르는 것과 가장 직접적으로 관련 있는 것은 최초로 체계가 잡힌 "컴퓨터-활용 보도" 혹은 "CAR" 이며, 더욱 향상된 뉴스를 제공하기 위해 데이터 수집과 분석을 위해 컴퓨터를 사용한 체계적 시도이다.
CAR은 1952 년에CBS에서 대통령 선거의 결과를 예측하기 위해 최초로 사용되었다. 1960년대 이후로 (주로 미국을 기반으로 조사하는 저널리스트들이 과학적으로 공공 기록 데이터베이스 분석하여 독립적으로 모니터링하는 방법을 추구했었다. 또한 "public service journalism"으로 알려진 이들의 컴퓨터-활용 기술의 지지자들은 트렌드를 파악하고, 일반적인 지식이 틀렸음을 증명하고, 공공 단체들과 법인들에 의해 저질러진 불법적인 것들을 드러내는 것을 추구했었다. 예를 들어, Philip Meyer은 디트로이트에서 일어난 1967 폭동에 대해 받은 기사가 틀렸음을 증명하였고, 이 폭동에 참가했던 사람들은 덜 교육받은 남부인들 뿐만이 아니라는 것을 보여주었다. 1980년대에 발행된 Bill Deadman의 "The Color of Money" 책은 주요 금융 연구소들의 제도적 인종 차별을 폭로했다. 그의 책인 "What Went Wrong?"에 있는 Steve Doig는 결함이 있는 도시 개발 정책과 관행들의 영향력을 이해하기 위해서 1990년대 초의 "허리케인 앤드루"의 피해 패턴 분석하는 것을 추구했다. 데이터-주도 보고는 가치 있는 공공 서비스를 초래했고, 그는 영예 기자상을 수상했다.
1970대 초반 취재의 새로운 형태인 이것을 설명하기 위해 "precision journalism"이라는 새로운 단어가 만들어졌다. : "저널리즘의 실천방법에 대한 사회과학과 행동과학의 갖가지 조사 방법의 적용". 정밀 저널리즘은 저널리즘과 사회과학 분야에서 전문적으로 훈련된 전문가들에 의해 주요 미디어 연구소들에서 실습되면서 가시화 되었다. 이것은 소설 기법이 보도에 적용되는 저널리즘의 형태인 "새로운 저널리즘"에 대한 반응으로부터 생겨났다. Meyer는 오히려 문학적인 기법 보다는 데이터 수집 및 분석을 하는 과학 기술이 객관성과 진실성에 대한 조사를 수행하는 저널리즘을 위해 필요하다고 제안하였다.
정밀 저널리즘은 저널리즘의 일반적인 인용의 부적절성과 약점 중 일부에 대한 반응으로 이해할 수 있다. : 대 언론 공식 발표(후세에서는 "churnalism(처널리즘)"으로 불리 우는)에 대한 의존과 권위 있는 출처에 대한 편견, 그리고 기타 등등. 이러한 것들은 Meyer에 의해 정보 과학 기술과 여론 조사와 공공 기록 같은 과학적 방법의 응용 부족으로부터 발생한 것으로 보여졌다. 1960년대 실행된 대로, 정밀 저널리즘은 비주류 집단과 그들의 이야기를 표현하는데 사용되었다. Meyer의 말에 따르면, :
"정밀 저널리즘은 이전에는 접근할 수 없었던 주제의 기사를 만들기 위한 기자의 도구 키트를 확장시키는 방법이었어요. 이것은 대의권을 위해 분투하는 소수 저항 집단의 의견을 듣는 공청회에서 특별히 유용했죠."1980년대에 보도 된 저널리즘과 사회 과학의 관계에 대한 영향력 있는 기사는 데이터 저널리즘에 대한 통상적인 담론에 대해 반향을 일으켰다. 미국 저널리즘 교수인 두 저자는 1970년대와 1980년대의 무엇이 뉴스인가에 대한 사회적 인식을 "뉴스 이벤트"의 편협한 시각으로부터 "situational reporting" 또는 사회적 추세에 대한 보도로 넓혀가는 것을 제안했다. 데이터 베이스(예를 들면, 인구조사 데이터나 측량 데이터)를 이용하면, 저널리스트는 "그들에게 상황정보가 의미 있게 제공되는 세부적이고 고립된 사건 보도를 너머로의 이동"을 할 수 있다.
우리가 예상한 대로, 보도를 향상시키기 위해 데이터를 사용하는 실천방법들은 주위에 "데이터"가 존재하기 시작한 때까지 거슬러 올라간다. Simon Rogers가 지적한 바와 같이, 데이터 저널리즘의 첫 사례는 1821년부터 가디언사에서 발생하였다. 그것은 맨체스터에 있는 학교들의 학교당 비용과 학생의 수를 목록화 한 유출된 표였다. Rogers에 따르면 이것은 공식적으로 발표된 숫자보다 훨씬 많은, 자유 교육을 받는 실제 학생들의 수를 처음으로 보여주는 것을 도왔다고 한다.
[그림] 1821년 가디언에 게재된 데이터 저널리즘
유럽의 다른 초기 예는 1958년에 출판된 Florence Nightingale과 그녀의 주요 보고서인 "Mortality of the British Army"이다. 의회에 제출한 그녀의 보고서에는 그녀는 영국 육군에 대한 의료 서비스 개선을 옹호하기 위해 그래픽을 사용했다고 한다. 가장 유명한 것은 그녀의 "coxcomb"(장미도표)이다. 이것은 섹션들이 나선형을 이루고 있는 것으로, 각 달의 사망자 수를 나타내고 있는데, 죽은 이들의 절대 다수는 총상 보다는 예방할 수 있었던 질병에 걸려 죽었다고 강조했다.
[그림] Florence Nightingale이 만든 영국 육군의 사망자 수 도표
데이터 저널리즘 그리고 컴퓨터-활용 보도
현재 "continuity and change(지속성과 변화)"와 이전 저널리즘 방법(데이터 세트를 분석하기 위한 전산 기법을 사용하는 방법)들과 이것들의 관계에 대한 토론이 "데이터 저널리즘" 주위에서 일어나고 있다.
CAR과 데이터저널리즘의 차이에 대해서 몇몇 의견 차이가 있다. 그들은 CAR은 (통상 조사하는)보도의 질을 높이기 위한 방법으로 단지 데이터를 분석하고 수집하기 위한 기술일 뿐이라고 말한다. 반면에 데이터 저널리즘은 저널리스트의 전체 작업 흐름에 연관되어 있는 데이터 시트자체에 주목한다. 이런 의미에서 데이터 저널리즘은 단순히 이야기를 찾거나 향상시키는 방법만큼(때때로는 더 많이, 데이터 그 자체에 주목하고, 단순히 데이터를 사용하는 것보다 더) 비용이 소요된다. 이런 이유로 우리는 가디언 데이터 블로그 또는 이야기와 함께 데이터 세트를 발표하는 Texas Tribune 또는 심지어 분석하고 탐구하는 사람들의 단순한 데이터 세트를 찾는다.
또 다른 차이점은 과거 조사 기자들은 그들이 대응하거나 언급하려 했던 이슈에 대한 문제와 관련 있는 정보의 부족으로 고생하곤 했다. 이것은 물론 아직도 여전히 사례일 뿐이지만, 이것은 또한 저널리스트들이 필수적으로 알아야 하는 정보가 아닌 정보의 압도적인 풍부함도 있다. 그들은 데이터가 아닌 것에서 가치를 얻는 방법을 모른다. 최근의 예는, 명백한 옹호 이후로 오랫동안 모색되었던, 그러나 발표된 이후로 많은 저널리스트들을 당황시키고 쩔쩔매게 했던 영국에서 가장 큰 지출 정보 데이터베이스인 COINS(통합 온라인 정보 체계)이다. Pilip Meyer가 최근에 나에게 이것을 써서 보낸 것은 다음과 같다 : "정보가 거의 없을 때에는, 우리 노력의 대부분은 정보를 찾고 모으는데 전념된다. 지금은 정보는 충분하기 때문에, 처리하는 것이 더욱 중요하다."
한 편, 일부는 데이터 저널리즘과 컴퓨터-활용 보도의 차이는 아주 근소한 것일 뿐이라고 주장한다. 현재의 관행에 의하면 심지어 최근 미디어 수행방법의 대부분은 역사 뿐만이 아니라 새로운 어떤 것도 내재하고 있다. 오히려 데이터 저널리즘에 대한 더욱 유익한 자세는 오랜 전통의 한 부분으로 그것을 받아들이는 것일 것이라는 견해가 완전히 소설인지 아닌지 논쟁하는 것 보다 새로운 상황과 조건에 대응해야 한다. 비록 목표와 기술에서의 차이가 없더라도, 세기 초의 "데이터 저널리즘"이라는 라벨의 출현은 이전보다 훨씬 더 많은 사람들이 더 많은 데이터를 이용하여, 더 쉽게 작업할 수 있도록 하는 정교한 사용자-중심 도구, 자기-출판 그리고 클라우드소싱 도구들과 결합하여 자유롭게 온라인으로 제공되는 데이터의 엄청난 양이라는 점에 대해서 새로운 국면을 나타낸다.
데이터 저널리즘이란 방대한 데이터를 읽고 사용할 줄 아는 능력
디지털 기술과 웹은 정보가 게시되는 방법의 근본적인 변화이다. 데이터 저널리즘은 데이터 시트와 서비스들 주위로 갑자기 생겨난 도구들과 방법들에 대한 생태계의 한 부분이다. 소스 자료의 인용과 공유는 웹을 비롯한 우리기에 익숙한 오늘날의 정보탐색구조에 사용되는 하이퍼링크 구조와 유사한 방식으로 이루어 진다. 더 멀리 거슬러 올라가면, 웹에 대한 하이퍼링크 구조의 근본 웹에 대한 하이퍼링크 구조를 기반으로 하는 것의 원칙은 학술적 작업에 사용되는 인용의 원칙이다. 이야기 뒤의 소스 자료와 데이터에 대한 인용과 공유는 위키리스크 설립자 Julian Assange가 "과학적 저널리즘"이라고 부른, 데이터 저널리즘이 저널리즘을 향상 시킬 수 있는 기본적인 방법들 중 하나이다.
누구나 데이터 원천 속으로 자료를 찾아 들어 가는 것과 그들에게 관련된 정보를 찾을 수 있게 하는 것 뿐만 아니라 사실 여부를 확인 하는 것과 일반적으로 받아들여지는 추정에 도전하는 것 을 가능하게 한 것을 통해, 데이터 저널리즘은 이전에 특정 분야의 전문가들(탐사기자들, 사회 과학자들, 통계학자들, 분석가들 또는 다른 분야의 전문가들 인지 아닌지 간에)만 사용하던 자료와 도구와 기술과 방법론들의 대중 민주화를 사실상 대표한다. 현재 데이터 원천의 인용과 연결은 데이터 저널리즘에 특별한 반면, 우리는 데이터가 미디어의 뼈대로 말끔히 통합되는 세계를 향해 움직이고 있다. 데이터 저널리스트는 데이터를 이해하고 데이터를 수집하는 장벽을 낮추는 것과 아주 많은 독자들의 데이터 활용능력을 높이는 것에 대해 중요한 역할을 하고 있다.
현재 그들 자신을 데이터 저널리스트들이라고 칭하는 사람들의 초기 커뮤니티는 더욱 성숙한 CAR 커뮤니티와 매우 큰 차이가 있다. 바라건대, 앞으로 우리가 새로운 NGO들과 시민 미디어 단체(ProPublica 및 탐사의 전통적 뉴스 미디어와 손을 잡고 일하는 탐사 보도의 Bureau 같은)에서 볼 수 있는 것 과 거의 비슷한 방식으로 두 커뮤니티 간에 강력한 유대관계를 볼 수 있길 바란다. 데이터 저널리즘이 데이터를 발표하고 기사를 제공하는 것에 대한 더 많은 창조적인 방법을 가지고 있을지라도, CAR 커뮤니티에 대한 철저하게 분석적이고 비판적인 접근은 데이터 저널리즘이 확실히 배워야 하는 그 무엇이다.
TAG :
이전 글 : DRM으로부터의 해방, 영원히
다음 글 : 데브옵스(DevOps)란 무엇인가?

최신 콘텐츠