IT/모바일
ML 모델이 업무상 중요한 문제가 되는 곳에서의 고려사항
이 게시물에서 내가 지난 9월에 New York trata Data Conference에서 제공했던 keynote가 담긴 슬라이드와 노트를 공유한다. data community에서 머신러닝 모델을 더 사용해서 나는 몇 가지 중요한 고려사항을 되짚어보고 싶었다
이 기술을 사용하는 상황부터 살펴보자. 우리가 최근에 실시한 설문에서 11,000명이 넘는 응답자한테 설문을 얻었는데 우리의 주요 목표는 기업들이 머신러닝을 어떻게 이용하는지에 대해 알아내는 것이었다. 우리가 알아낸 것 중 하나는 많은 기업들이 아직도 머신러닝을 초기 단계의 것으로 사용하고 있다는 것이다.
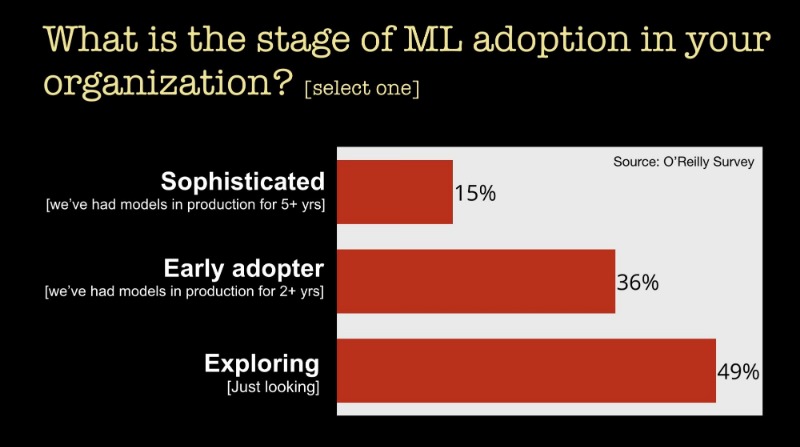
기업들이 뒤떨어지는 이유에 대해서 우리는 이번년도 초에 실시한 설문에서 기업들은 기술을 사용하는 것을 방해하는 주요 과제로써 기술자가 없다, 즉 “기술격차” 라고 언급했다.
기업 측의 관심은 머신러닝 인재에 대한 수요가 풍부하다는 것을 의미한다. 개발자들은 머신러닝에 주목해왔고 그것을 배우기 시작했다. 온라인으로 교육을 받을 수 있는 플랫폼으로 (210만명 이상의 유저가 있는) 우리는 머신러닝 주제에 관심이 높다는 것을 발견했다. 아래의 것은 교육 플랫폼의 상위 검색 주제이다.

검색을 넘어 우리가 책과 게시물 비디오 교육과 같은 모든 형태에서 머신러닝에 관련된 컨텐츠 소비의 엄청난 성장을 목격하고 있다는 것을 주목해라.
내가 계속 진행하기 전에, 머신러닝이 모델을 구축하는 것보다 더 중요하다는 것을 강조하는 것이 중요하다. 많은 모델을 상품과 서비스에 적용하기 전에 먼저 문화와 프로세스와 인프라를 갖춰야 한다. Strata Data 컨퍼런스에서 관련된 문화와 조직, 엔지니어링에 대한 주제에 대한 이야기를 했다. 여기서 최근의 컨퍼런스의 관련된 세션 목록입니다.
- 데이터 통합 및 파이프라인
- 데이터 플랫폼
- 모델 주기 관리
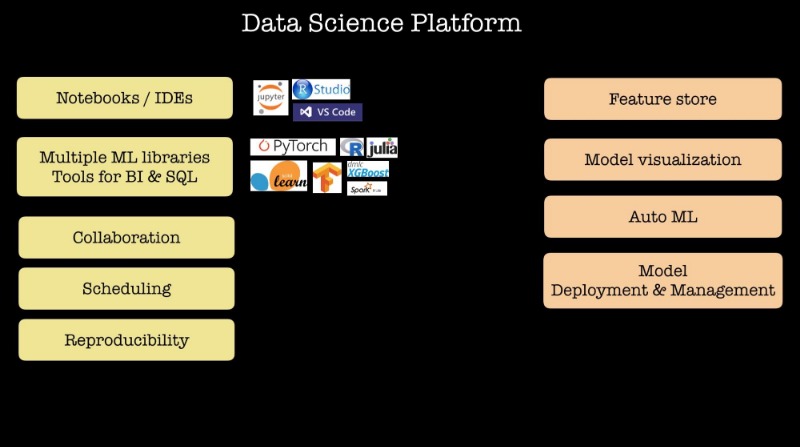
지난 12개월에서 18개월 동안 많은 머신러닝을 사용하고 많은 데이터사이언티스트를 고용한 회사들은 내부 데이터 사이언스 플랫폼을 설명해왔다. (넷플릭스나 트위터, 페이스북같은). 그들은 많은 머신러닝 라이브러리와 프레임워크와 노트북과 스케줄링과 협업에 대한 지원을 포함하여 내가 아래에 적은 리스트들의 특징을 공유한다. 몇몇 회사들은 데이터 사이언티스트들이 머신러닝에서 이용된 피쳐들을 공유하는 방법, 가능성 있는 모델을 자동적으로 찾는 도구와 같은 진보된 기능이 포함되어 있고, 몇몇 플랫폼에는 모델 구축 기능 또한 포함되어있다.
시제품 제작을 넘어 실제로 머신러닝 모델을 구축하면 실제 유저들이나 디바이스가 모델과 상호작용 하기 시작할 때 많은 문제들이 발생할 것이다. David Talby는 최근의 게시물에서 이러한 몇가지 중요한 과제를 요약해놓았다.
- 당신의 모델은 정확도에서 성능이 저하된 채로 시작될 것이다
- 모델은 맞춤화 해야한다 (특정 장소와 문화와 도메인과 어플리케이션에서)
- 실제 모델링은 프로덕션에서 시작된다
통계적이거나 정량적인 지표를 최대화 시키는 것을 넘어 많은 고려사항이 있다. 예를 들어 신용 평가나 헬스 케어같은 특정한 지역이 있는데, 거기서 설명될 수 있는 모델을 요구할 수 있다. 특정 적용 도메인에서는 (자율주행이나 의료를 포함한) 안전 및 오류 추정치가 무엇보다 중요하다. 실생활에 머신러닝을 많이 배치하기 때문에 통계적이거나 비즈니스적인 지표를 최대화 하는 것으로 충분하지 않을 것이다. 데이터 사이언티스트 커뮤니티는 점점 두 개의 토픽으로 이루어지는데 그것은 우리가 나머지 게시물에서 언급하고 싶은 것이다. 그것은 사생활 침해와 머신러닝의 공정성이다.
사생활과 안전성
유저들과 규제기관에서 데이터 프라이버시에 대한 관심이 높아지고 있다면, 데이터 프라이버시를 지켜줄만한 머신러닝을 만들어 줄 도구에도 관심이 있을 것이다. 이러한 도구들은 블록에 달려있고 우리들은 이러한 많은 빌딩 블록을 결합하는 작업 시스템을 보기 시작하고 있다. 어떤 도구는 오픈소스이고 좀 더 광범위한 데이터 커뮤니티에 의해 사용 가능 하게 되고 있다.

-
개인적인 데이터를 공유하지 않고 협동하고 싶거나 집중식 모델을 구축하고 싶을 때 통합학습(Federated learning)은 굉장히 유용하다. 이것은 구글에서 사용되고 있지만 우리는 아직 광범위하게 접근가능하게 만들어진 툴이 필요하다.
-
우리는 가장 인기 있고 파워풀한 프라이버시 정의 중 하나인 차별화된 프라이버시를 보장하면서 모델을 구축하게 해주는 도구들을 보기 시작했다. 높은 수준에 있는 이러한 도구들은 모델 제작 프로세스의 다른 단계에서 무작위 노이즈를 더한다. 이러한 최근에 생겨난 툴들은 이미 사이킷런이나 텐서플로우같은 라이브러리를 사용하는 데이터 사이언티스트에 접근 가능하게 하기 위한 목표를 두고 있다. 이러한 목표는 데이터사이언티스트들의 곧 일상적으로 다른 개인적인 모델을 만들길 바란다.
-
암호화된 데이터로 머신러닝 모델을 사용하거나 제작할 수 있는지 연구하는 소규모이고 증가하고 있는 많은 연구자들과 기업가들이 있다. 작년에 우리는 빠른 동형 암호화를 위한 오픈소스 라이브러리 (HElib과 Palisade) 보았고 우리는 이러한 라이브러리 위에서 머신러닝 툴과 서비스를 제작하는 스타트업을 가지고 있다. 여기서 방해하는 주요 요인은 속도다. 많은 연구자들이 실제로 하드웨어와 소프트웨어 툴을 연구하고 있는데 이 툴들은 암호화 데이터에서 모델 추론을 빠르게 해줄 수 있다. (아마 모델 구축까지도)
- 안전 멀티 분산(Secure multi-party computation)은 또 하나의 이러한 분야에서 유망한 기술이다
공정성
지금 우리는 공정성을 고려한다. 지난 2년 동안 많은 머신러닝 연구자들과 현업자들이 머신러닝 모델이 공정하고 정의롭도록 하는 도구를 연구하고 발전했다. 바로 요 전날 AI에 관한 구글의 최신 기사를 검색했더니 공정성에 관한 기사가 많아서 놀랐다
나머지 섹션에서 우리는 분류기를 구축하고 특정한 변수가 보호되는 특성으로 간주된다고 해보자. (이것은 나이, 민족, 성별 등도 포함될 수 있다) 이것은 머신러닝 연구자 커뮤니티가 분류기가 공정하다는 것이 무엇을 의미하는지를 정의하는 많은 수학적인 기준을 사용하고 있다는 것을 보여준다. 운이 좋게도 스탠포드에서 나온 설문 조사 보고서 A Critical Review of Fair Machine Learning에서 이러한 기준을 단순화하고 그러한 기준들을 다음의 종류의 척도로 그룹핑한다.

-
반분류(Anti-classification)는 모델과 분류기으로부터의 보호된 속성과 이러한 대용물을 생략한 것을 의미한다.
-
분류 동등성(Classification parity)은 하나 혹은 그 이상의 표준적인 성능 척도(1종 오류, 2종 오류, 정확도, 재현율)가 보호된 속성에 의해 정의된 그룹 전체에서 같다는 것을 의미한다.
- 눈금측정(Calibration)은 만약 알고리즘이 스코어를 만들어 낸다면 스코어는 다른 그룹에서도 같은 것을 의미해야한다.
그러나 스탠포드의 다른 저자들이 이러한 보고서에서 지적했듯이 각각의 수학적인 공식은 한계 부딪힌다. 공정성에 관해 깔끔하게 당신의 알고리즘을 주장할 수 있는 블랙박스나 일련의 과정이 없다. 하나의 사이즈에 모든 것이 맞을 수 없다.
왜냐하면 빈틈이 없을 정도로 철저한 과정은 없기 때문에, 팀이 필요할 것이다. 공정성이라는 관념은 단지 도메인이나 상황에 민감할 뿐만 아니라, UC Berkeley으로부터의 연구자들이 지적했듯, 시간 측면 또한 있다 (우리는 공정한 머신러닝에 대한 논의에 대한 장기적 관점을 옹호한다) 필요한 것은 데이터를 얻을 수 있고 기초적인 분포를 이해할 수 있는 데이터사이언티스트들이다. 그리고 그들이 모델을 전체적으로 평가할 수 있는 도메인 전문가들과 같이 일해야한다.
문화와 조직
우리가 더 많은 모델을 만든 후 우리가 통계적이고 비즈니스적인 지표를 넘어서 생각해야한다는 것이 필요하다는 점이 명확해지고 있다. 짧은 게시물에서 우리는 이 점을 다루지 않았지만 신뢰성과 안전성이 굉장히 중요해지고 있다는 것은 명확하다. 어떻게 머신러닝이 다른 많은 중요한 일을 설명해야 하는 세상에서 팀을 만들고 조직할 것인가?

운이 좋게도 데이터 커뮤니티에는 많은 멤버들이 있다. 그리고 그들은 이러한 문제들을 생각해왔다. 프라이버시 포럼과 Immuta의 미래에서 최근에 리스크 관리를 염두해두고 어떻게 머신러닝 프로젝트를 접근해야 하는지에 대한 굉장한 제안을 하는 보고서를 냈다.
-
우리가 머신러닝 프로젝트를 할 때 데이터 엔지니어와 데이터 사이언티스트와 도메인 전문과들을 모두 고용해야한다
- 리포트 개요에 있는 한가지 중요한 변화는 우리는 모델 구축 팀으로부터 독립된 일련의 데이터 사이언티스트가 필요하다. 이러한 팀은 설명성과 프라이버시, 공정성 측면에서 머신러닝 모델을 평가하는 일을 할 수 있다.
마치며
그래서 어떤 스킬이 머신러닝 모델이 중요한 임무가 되는 세계에서 필요한가? 말했듯, 공정성 검토는 데이터 전문가와 도메인 전문가가 혼합해서 해야한다. 사실은 최근 NBER의 채용 공고에서 분석에서 데이터 분석 스킬과 비교해서 머신러닝 스킬은 도메인 지식과 같이 있어야한다.
그러나 또한 데이터 전문가와 도메인 전문가와 더불어 법 전문가와 안전 전문가 또한 보충해야 할 것이다. 앞으로 우리는 데이터 사이언티스트와 데이터 엔지니어링과 밀접하게 법적이고 규정 준수, 안전에 관한 전문가 또한 필요할 것이다.

이것은 놀랄 일이 아니다. 우리는 이미 컴퓨터 보안, 웹 보안, 모바일 보안에 투자했다. 머신러닝이 소프트웨어까지 장악한다면 우리는 인공지능과 머신러닝 보안까지도 고심해야 할 것이다.
*****
원문 : Managing risk in machine learning
번역 : 박규리
이전 글 : 이제 웹을 다시 세울 시간입니다

최신 콘텐츠